
If you compile all the data from a single protocol in one excel sheet., where you have the date of the experiment in one of the columns, and the assay results in the other columns, then this file can be imported directly into CDD. This will be one single upload into one Run Date and the experiment date will be mapped into an Experiment Date Readout within your Protocol. Therefore the date of the experiment is preserved for future reference.
Here's a work-flow that will permit you to import multiple runs from a single file: You will manually create all of the runs ahead of time. Then you will rearrange the file a bit: molecule IDs and/or plate data will be in one column, regardless of run date, but the protocol data is broken up into separate columns for each run. Lastly, you will map your columns to the individual runs you've already prepared.
That was the quick outline. Now let's do it step-by-step.
Here's what your file might look like:
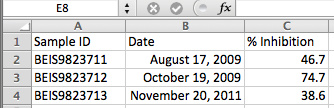
1. Create all runs
Go to the protocol details page by clicking on the protocol name.
On the Run Data tab, click  Create a new run link and manually create your first run. To simplify this repetitive task, just copy/paste the date from your original excel file. Repeat for each run. For the example in the screen-shot above, you will have 3 runs: 08/17/2009, 10/19/2009 and 11/20/201.
Create a new run link and manually create your first run. To simplify this repetitive task, just copy/paste the date from your original excel file. Repeat for each run. For the example in the screen-shot above, you will have 3 runs: 08/17/2009, 10/19/2009 and 11/20/201.
2. Rearrange the import file
Following the shown example, create 3 "% Inhibition" columns- one for each Run Date.
Move the % Inhibition data into the appropriate column, and don't forget to save as a CSV file.

3. Import the rearranged file into the protocol, using previously created runs from step 1.
In the second import step, map the Sample ID as Batch External Identifier (or if you're using plate and well, then map these fields).
Skip Columns B and C (Date and % Inhibition), and map Column D to Run 08/17/2009,
Column E to Run 10/19/2009, and
Column F to Run 11/20/2011 respectively.
In this fashion, you can import data from multiple runs from a single file, or even data from multiple protocols. For example, imagine that instead of having 3 different run dates for these three molecules, we had instead inhibition data from 3 different assays. The file layout of the import file would remain the same, but in the mapping step, instead of choosing different runs of the same protocol, you would choose a different protocol for each % Inhibition column.