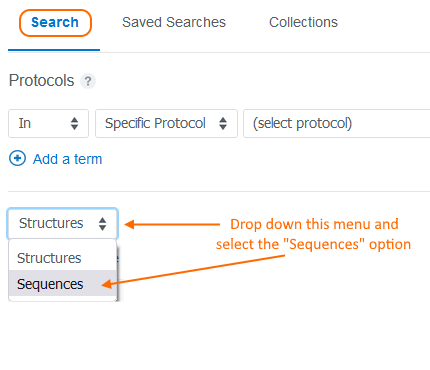
When your CDD Vault is configured to allow the registration of the Amino Acid or Nucleotide registration entity types, a new drop-down menu will appear in the Explore Data > Search tab.
A powerful feature for querying Amino Acid and Nucleotide sequences is now available. The new sequence search box will appear in place of the structure editor on the Explore Data > Search tab. If structure and a sequence registration type is enabled in your Vault, you’ll see a drop-down menu with the option to search “Sequences”.
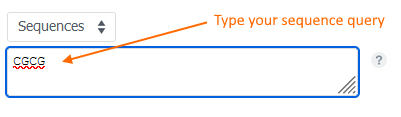
To search, enter the desired amino acid/nucleotide query (using 1-letter codes) into the Sequence text box and click the green “Search” button.
Helpful Hints
- By default, the search query matches any sub-string in the results.
- Only single-letter amino acid (and nucleotide) codes are permitted in the search query.
- Exact search is not supported.
- All spaces, newline characters, and double quotes are stripped from the query.
- The search query follows regular expression syntax. Therefore, certain characters will be interpreted as reserved regular expression operators, i.e. * will match any number of codes (including 0) while ? will match at most one code.
- To support complex queries and ambiguous code searching, both the length and complexity of your query string apply to the complexity limit.
- An ambiguous code matches itself and any code within its set of possible codes, i.e. nucleotide code N (any base) matches N, A, G, C, T, and U in addition to all other ambiguous nucleotide codes.
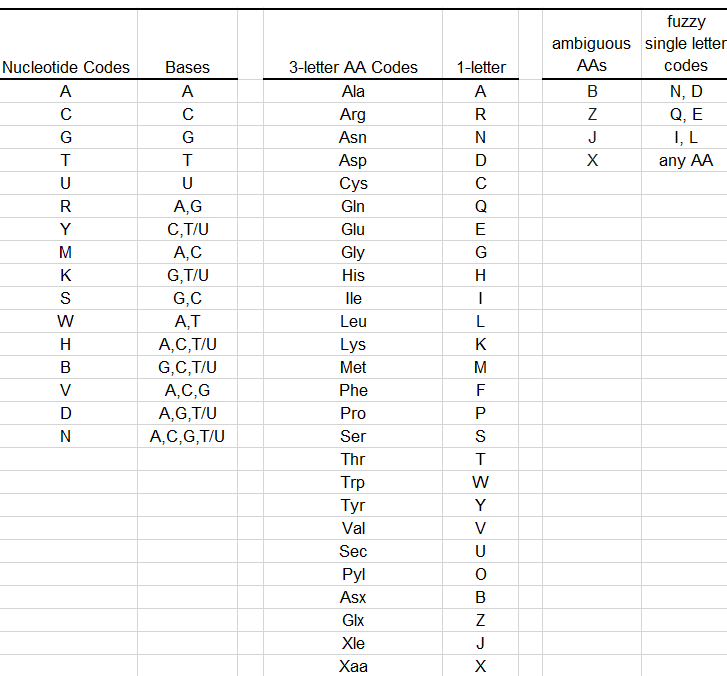
Here is the full list of supported nucleotide and amino acid codes: